
Se doblan pero no se rompen
Investigadores argentinos construyeron un modelo matemático que permite inferir cómo se produce el plegado de miles de proteínas y cómo evolucionan. El dispositivo tiene una aplicación directa para el diseño inteligente de proteínas, un campo del desarrollo nanotecnológico que está en plena expansión para usos médicos e industriales.
Un equipo de investigadores de la Facultad de Ciencias Exactas y Naturales de la UBA dio un paso clave para comprender cómo se produce el plegado de las proteínas y cómo evolucionan estas moléculas, al construir un modelo matemático para inferir el mecanismo de plegado de miles de proteínas. El dispositivo tiene una aplicación directa para el diseño inteligente de proteínas, un campo de desarrollo nanotecnológico que está en plena expansión en todo el mundo y que es incipiente en la Argentina. Facilitaría, por ejemplo, la producción de sistemas de proteínas para uso clínico, como fármacos o vacunas, y para usos industriales, como los biocombustibles.
“Las proteínas son las moléculas más maravillosas que podemos encontrar en la escala molecular de lo viviente”, comienza el biólogo Diego Ferreiro, investigador del Instituto de Química Biológica (IQUIBICEN, UBA – CONICET) y docente de Exactas UBA. Las proteínas son verdaderas nano-máquinas que hacen posible las realidades químicas que nos constituyen como seres vivos.
Llamamos con ese nombre genérico a un gigantesco conjunto de moléculas muy diferentes entre sí, que desarrollan cada una de las funciones necesarias para la vida: la regulación de la expresión genética, el crecimiento y la diferenciación celular, la respiración, la fotosíntesis, etcétera.
Lo que hace cada proteína depende de su forma. Como en el arte del origami, las proteínas adquieren sus estructuras plegándose. Son las cadenas de aminoácidos que las constituyen las que se pliegan sobre sí mismas. Ahora bien, ese “diseño” de las formas proteicas viene dado por la evolución de sus estructuras, por los cambios que ocurren en ellas a lo largo de millones de años.
Lo que hace cada proteína depende de su forma. Como en el arte del origami, las proteínas adquieren sus estructuras plegándose.
En un trabajo publicado en la revista Proceedings of the National Academy of Science, los investigadores del Laboratorio de Fisiología de Proteínas del IQUIBICEN presentaron un modelo teórico y una aplicación computacional para entender y simular el plegado de una familia entera de proteínas. “Tomamos información de las estructuras de proteínas existentes y construimos un modelo matemático que describe las variaciones evolutivas observadas”, describe Ezequiel Galpern, tesista doctoral y principal autor del trabajo desarrollado en colaboración con un laboratorio francés. Ese modelo sirvió de base para construir simulaciones computacionales del proceso de plegado de las proteínas, relacionando la información evolutiva con la fisicoquímica.
“Los aminoácidos que componen las proteínas son siempre los mismos, veinte aminoácidos de cuyas diferentes combinaciones resulta la maravillosa biodiversidad que tienen las proteínas –explica Ferreiro–. La gran mayoría de las secuencias de aminoácidos no se pliegan en estructuras compactas, funcionales, biológicamente relevantes. Solamente una fracción muy minoritaria de las posibles secuencias forman esas estructuras. Y en esas secuencias hay información sobre la capacidad de plegarse una proteína o una familia de proteínas”.
El tipo de plegamiento de las proteínas depende del modo en que se van conectando los aminoácidos en las cadenas. Hay una estructura primaria que es la propia secuencia de aminoácidos unidos por enlaces peptídicos; una secundaria, por la que la cadena rota o se dobla, adquiriendo forma de hélice o de lámina plegada, y una terciaria, por la cual la cadena polipeptídica se pliega sobre sí misma. La estructura cuaternaria, por fin, deriva de la conjunción de varias cadenas en el espacio.

Ezequiel Galpern. Foto: Exactas UBA.
“Ahora bien, sabemos que si dos aminoácidos están cerca en la estructura tridimensional, aunque estén lejos en la estructura primaria, es probable que si uno de esos dos elementos cambia al azar, el otro forzosamente también deba cambiar para que la secuencia mantenga ese plegado estable –explica Galpern–. Si no ocurre esa coevolución, es poco probable que uno encuentre esa secuencia en una proteína natural, porque esencialmente podría no funcionar. En ese sentido, los cambios al azar están modulados por la selección natural, que tiene esta información de qué cosas funcionan y qué cosas no. De alguna manera, estas maquinarias decodifican la información del entorno para ir encontrando secuencias que sean funcionales. Ese es el desafío de la ciencia: si uno pudiera desentrañar el misterio de qué aminoácidos, qué elementos de este alfabeto tiene que elegir y poner en cada lugar para adquirir un cierto plegado, que cumpla cierta función, uno podría diseñar cadenas nuevas de aminoácidos, nuevas proteínas para diseñar fármacos y para diversos usos de la biotecnología. Eso es hoy, digamos, el Santo Grial de la biología molecular: qué tengo que poner para producir una proteína que haga exactamente esto. Eso hoy no se sabe. Nosotros nos embarcamos en el intento de navegar esas aguas y encontrar algún rumbo.”
“Para eso nos centramos en un sistema de proteínas repetitivas, la familia de las ankirinas –puntualiza Ferreiro–, que tienen una estructura de plegado repetitiva y simétrica, lo que permite un mapeo sencillo entre la estructura primaria y la terciaria. Lo que construimos, a partir de la información evolutiva presente en este tipo de proteínas, es un sistema de ecuaciones que relaciona las posiciones de los aminoácidos, y así obtener un modelo que permita inferir cómo se va armando la arquitectura tridimensional de estas proteínas.”
“Las proteínas son las moléculas más maravillosas que podemos encontrar en la escala molecular de lo viviente”.
Con las secuencias de la misma familia de proteínas de distintas especies de mamíferos, por ejemplo, es posible verificar en qué posiciones de la cadena van variando los aminoácidos, y en qué sitios, cuando se opera un cambio evolutivo, “co-ocurre” con otro. Entonces, a partir de la frecuencia de ocurrencia y co-ocurrencia de posiciones y modificaciones, y en el caso de las proteínas repetitivas, la duplicación de repeticiones o su deleción, el modelo matemático desarrollado deduce las formas que adquirirá el plegado de unas cuatro mil proteínas.
En efecto, la simulación mostró que los mecanismos de plegado se correspondían con las observadas en investigaciones experimentales, lo que pone de manifiesto la validez de su aplicación. “Hacer experimentos para analizar la dinámica del plegado de una proteína es muy costoso y puede llevar años. Nuestro algoritmo predice el plegado en pocos minutos”, resalta Galpern.
Lo que permite este modelo matemático, agrega Galpern, es “entender cuáles son las restricciones. Si algo sucede siempre, es muy probable que constituya la versión más estable del plegado de una proteína. Si ocurre algo completamente azaroso, lo más probable es que la cadena no se pliegue o que sea un plegado muy inestable. Lo que hicimos fue cuantificar esa relación entre la diversidad natural y la estabilidad del plegado. Y como las proteínas repetitivas tienen módulos, pudimos calcular la estabilidad de cada módulo, y de esa manera computar no sólo cuán estable es el plegado general, sino también qué fragmentos de la secuencia se pliegan antes que otros, cuáles ocurren al mismo tiempo, etcétera”.
El dispositivo tiene una aplicación directa para el diseño inteligente de proteínas, en desarrollos nanotecnológicos para uso clínico e industrial.
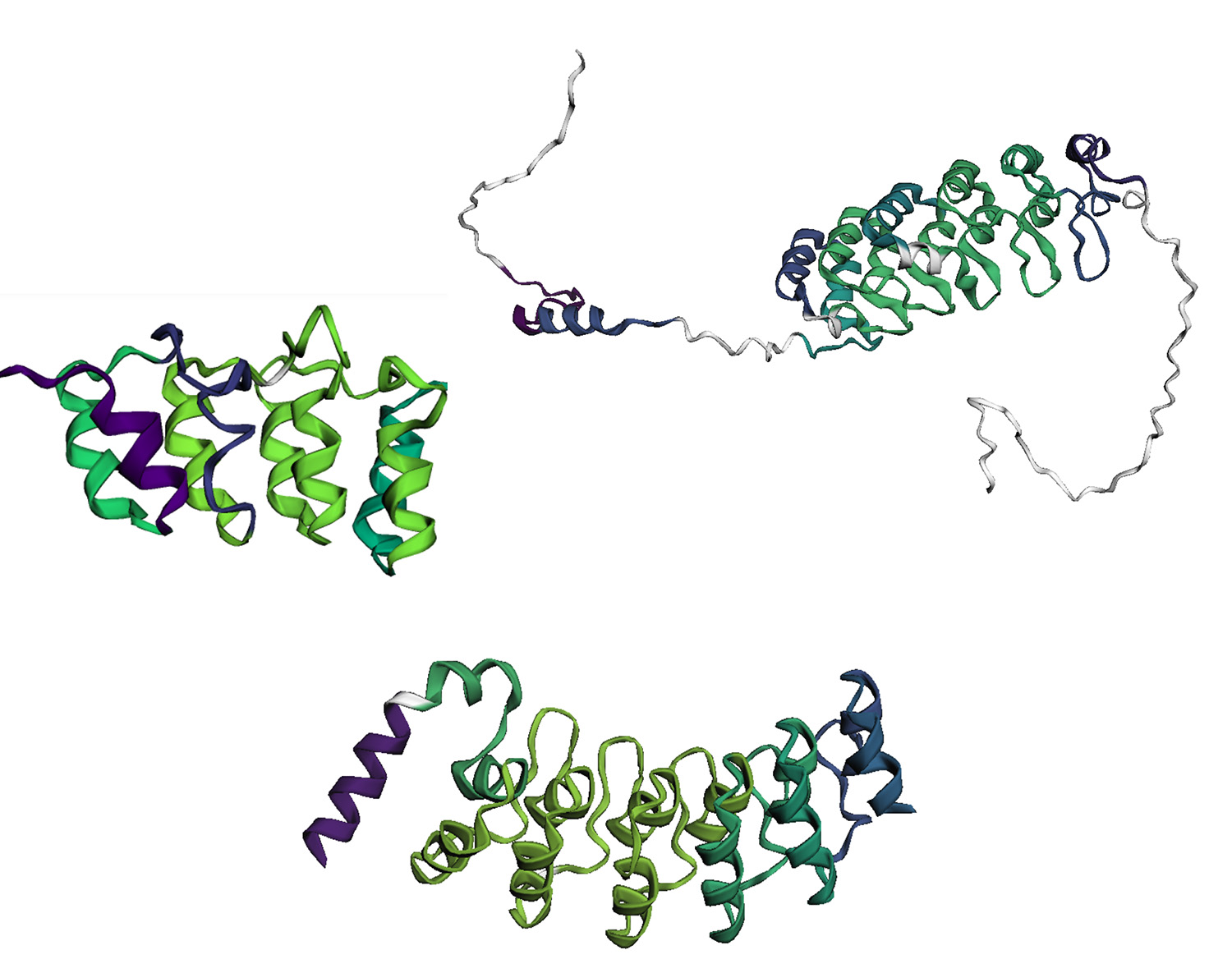
Tres proteínas repetitivas (IkBa, p16 y receptor Notch) coloreadas según la estabilidad de plegado de cada elemento. Amarillo-verde: elementos estables. Azul-púrpura: elementos más inestables. Gris: fragmentos no repetitivos.
“Ahora bien, las proteínas tienen que ser suficientemente estables para plegarse pero necesariamente inestables para funcionar. De lo contrario, no evolucionarían, serían piedras, hermosas pero inmóviles”, advierte Ferreiro respecto del delicado equilibrio que debe buscarse en el diseño de proteínas. “Lo que nosotros logramos, entonces, es un método matemático que infiere la estabilidad de cada proteína e informa, también, cuáles son los tramos inestables y cuán inestables son.”
En consecuencia, el modelo desarrollado abre las puertas a la posibilidad de manipular este aspecto fundamental de las proteínas. “Mucho de la nanotecnología moderna se basa en la biomímesis, utilizando sistemas biológicos o parecidos a los biológicos, a los que les reconocemos algún tipo de funcionalidad codificada que todavía no sabemos diseñar a escala nanométrica. Y el diseño de estos sistemas –concluye Ferreiro– depende de la estabilidad de los componentes con los que se construyen.”
“Pero además de predecir qué les pasa a las secuencias existentes –cierra Galpern–, este modelo también es un motor que genera secuencias posibles, con parámetros y dinámicas de plegado similares a las naturales. Por supuesto, este es un modelo sencillo, desarrollado a partir de proteínas repetitivas, pero aspiramos a poder identificar cuáles son los módulos o los elementos de plegado de otras familias de proteínas, más complejas, y ampliar este modelado a cualquier tipo de proteína. Eso hoy no existe. Esto es un primer paso.”