
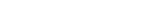
Una voz en la computadora
Una persona, con sólo tres detectores en la boca, hace la mímica de lo que quiere decir y la computadora habla por ella. Hasta el momento, los científicos lograron reproducir la mitad de los fonemas del español, y siguen investigando para alcanzar un aparato vocal virtual con todos los sonidos posibles. El desarrollo puede tener aplicaciones en el ámbito de la salud.


http://nexciencia.exactas.uba.ar/audio/aDiptongos.mp3
Descargar archivo mp3 de Diptongos pronunciados por voz sintética
http://nexciencia.exactas.uba.ar/audio/aaVocales.mp3
Descargar archivo mp3 de Vocales pronunciadas por voz sintética
http://nexciencia.exactas.uba.ar/audio/MarcosTrevisan.mp3
Descargar archivo MP3 de Marcos Trevisan
Con solo tres detectores colocados en la boca y conectados a una computadora, se logró reproducir con voz sintética lo que una persona deseaba expresar. Se trata de una prueba experimental que por ahora permite hacer oír la mitad de los fonemas del español, mientras continúan los estudios para alcanzar un aparato vocal virtual que llegue a transcribir cualquier sonido.
“La persona hace la mímica de lo que quiere decir y la computadora habla por ella”, resume en pocas palabras su experimento Marcos Trevisan, desde el Departamento de Física de la Facultad de Ciencias Exactas y Naturales de la Universidad de Buenos Aires (Exactas UBA). “Uno se imagina aplicaciones más o menos inmediatas a nivel salud, y también académicas, dado que aún hay mucho por conocer sobre el control motor. Ni siquiera está resuelto cómo es el modelo que usa el cerebro para mover el brazo y alcanzar un objeto”, agrega.
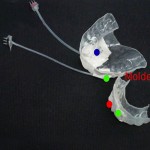
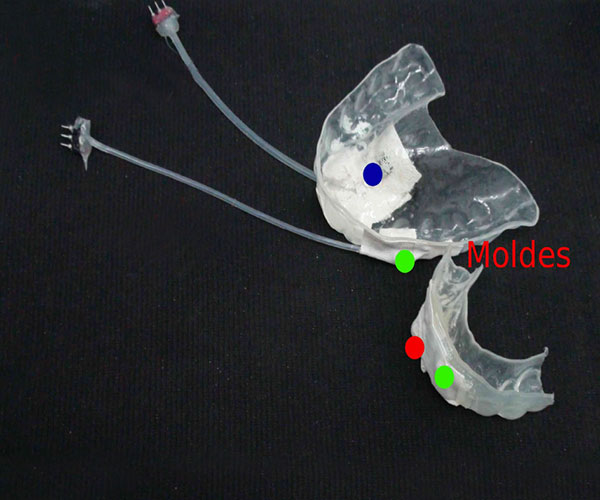
En el Laboratorio de Sistemas Dinámicos del Pabellón I de la porteña Ciudad Universitaria, el equipo de científicos coloca moldes dentales en la boca de José, parecidos a los que usan los dentistas pero tienen minúsculos aparatos. “Uno va en la lengua, otro en los labios y el restante en la mandíbula. Con sólo esos tres detectores, que mandan sus señales a la computadora, puedo generar voz sintética”, indica Trevisan.
Ahora bien, ¿qué hace un físico en esta investigación? “Básicamente reproducimos la física que sucede dentro del aparato vocal cuando uno habla. Para producir la voz, el sonido viaja en la cavidad que va desde la salida de las cuerdas vocales hasta los labios. Esta cavidad, llamada tracto vocal, funciona como una guía de ondas para el sonido, de manera que el repertorio vocal depende de su configuración, que cambia en forma continua durante el habla. Tenemos un modelo matemático, que reproduce a la manera de la física, cómo se mueven las cuerdas vocales y cómo viaja el sonido en el tracto vocal”, explica.

Marcos Trevisan.
Trevisan y su grupo pueden simular el movimiento de las cuerdas vocales y cómo progresa la onda sonora mientras va viajando en las cavidades del organismo hasta que sale de los labios y logra ser oída. “El problema era cómo alimentar con datos anatómicos ese modelo computacional para que genere una voz sintética a partir de ellos. No estaba claro cuántos datos necesitábamos”, relata.
Requería colocar dos, tres, cinco o siete sensores en la boca para obtener información sobre todo el mecanismo que entra en acción cuando hablamos? Tras diversos estudios, los resultados sorprendieron porque era menos complicado de lo sospechado. “Basta con recoger tres señales de ese tracto vocal complejo para generar la voz sintética. Esto es para un cuerpo de la mitad de los fonemas del español”, precisa.
Con esta investigación llegaron a ser audibles o sintetizadas las vocales y los fonemas oclusivos, “plosivos o explosivos, que son las que se percibe que provienen como un arranque repentino del tracto vocal, como la p, t, d”, puntualiza. Con la mitad de los fonemas del español resueltos para ser escuchados, el equipo busca lograr lo mismo con la parte faltante. Y, en realidad, va por más. “Tratamos de reproducir el sonido vocal genérico de todas las lenguas”, indica.
Si finalmente es posible sintetizar la voz con todos sus sonidos mientras una persona hace mímica, las aplicaciones podrían ser muy saludables. “La idea es que la computadora resuelva con datos anatómicos la generación del habla. Por supuesto, la aplicación inmediata que a uno se le ocurre es poder hacer hablar a alguien que no puede. De hecho, hay mucha gente que no puede hablar porque no puede mover las cuerdas vocales pero puede mover su tracto vocal”, concluye.



