
Modelo para desarmar
Con su reciente popularidad, la inteligencia artificial inspira tantas amenazas como promesas. ¿Es razonable desconfiar de esta tecnología? ¿Superará al intelecto humano? ¿Se deben frenar los desarrollos? En diálogo con NEXciencia, Luciana Ferrer, especialista en el tema e investigadora del CONICET, despeja algunas dudas y comenta sus trabajos.
Hasta en la sopa. En los últimos meses, la inteligencia artificial (IA) pasó a ocupar el centro de la escena. Está en las mesas familiares, las charlas de oficina, la televisión, las redes sociales. Ya ingresó en el salón de la fama de la cultura popular y hasta tuvo sus escándalos mediáticos. Con tanto ruido, las dudas y mitos se instalan con más fuerza que sus posibilidades concretas.
La historia es conocida. Desde el lanzamiento de Chat GPT, desarrollado por OpenAI, a fines de 2022, se han generado iguales dosis de fascinación y espanto. En ese contexto, dos hechos marcaron la agenda. El primero fue la carta abierta firmada por expertos y empresarios, encabezada por Elon Musk, alertando sobre los “grandes riesgos” y proponiendo suspender los desarrollos por seis meses. El segundo fue la renuncia de Geoffrey Hinton a Google tras calificar de “aterrador” a Bard, el chat bot de esa compañía, apuntando a su falta de ética y a la necesidad de regulaciones.
En el medio, un grupo de científicos y especialistas en IA reunidos en Montevideo en el marco de Khipu, el Encuentro Latinoamericano de Inteligencia Artificial, firmó una declaración respondiendo críticamente a la carta encabezada por Musk. “No hay valor social en tecnologías que simplifican tareas a unas pocas personas generando alto riesgo para la dignidad de muchas otras, limitando sus oportunidades de desarrollo, su acceso a recursos y sus derechos”, advierten al afirmar que la implementación de IA debe cumplir con los principios rectores de los derechos humanos y estar al servicio de las personas.
¿Para qué estamos utilizando esta tecnología? ¿Nos quedaremos sin trabajo?¿Hemos abierto una caja de Pandora sin ningún control?
En definitiva, ¿para qué estamos utilizando esta tecnología? ¿Nos quedaremos sin trabajo? ¿Las máquinas tendrán autonomía y poder de decisión sobre asuntos públicos? ¿Hemos abierto una caja de Pandora sin ningún control? Son preguntas que ya están sobre la mesa. Sin embargo, para evitar tanto el optimismo furtivo como la distopía fatal, puede ser útil empezar por lo básico.
¿Cómo definir la Inteligencia artificial? Para Luciana Ferrer, investigadora del Laboratorio de Inteligencia Artificial Aplicada en el Instituto de Ciencias de la Computación de la Facultad de Ciencias Exactas y Naturales de la UBA, son algoritmos y métodos que puedan resolver los mismos problemas que nosotros aunque, potencialmente, de otras maneras.
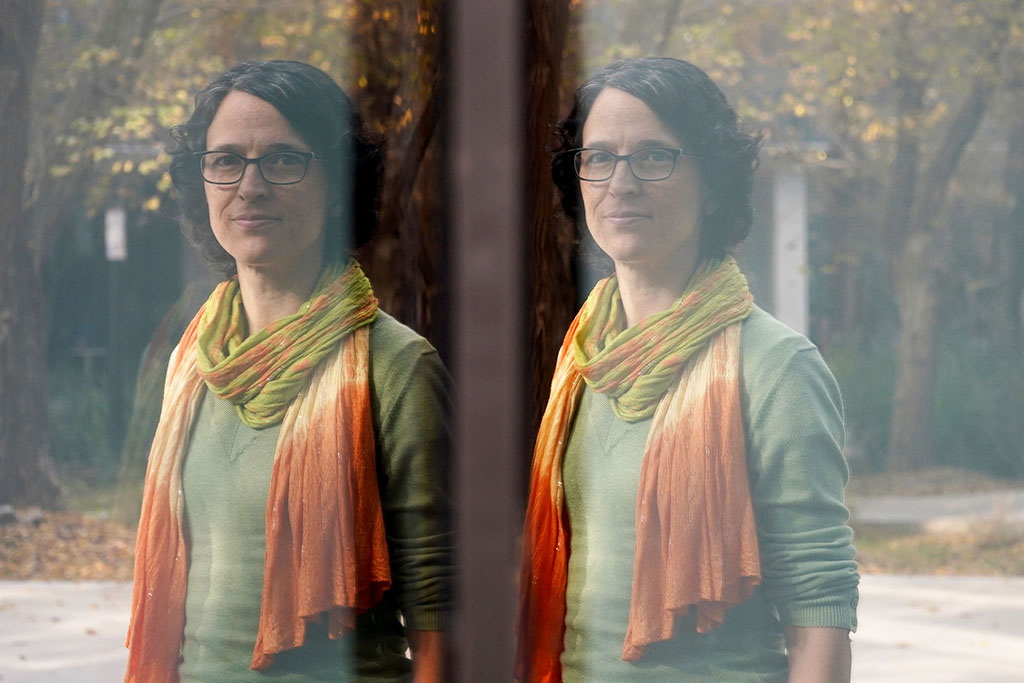
Luciana Ferrer. Foto: Luiza Cavalcante. Exactas UBA.
“Lo que llamamos inteligencia artificial es un concepto que existe, aproximadamente, hace noventa años”, afirma. Y explica: “En aquel momento, estaba basado en sistemas expertos diseñados por especialistas que tomaban las decisiones de forma manual, dando instrucciones explícitas. En cambio, ahora se aprende de datos. Conceptualmente es bastante similar: contás con cierta información de tu problema y tenés una caja negra que dice qué hacer en cada caso. Lo que hay dentro de ella lo aprendemos de una gran cantidad de datos, y lo que trata de aprender ese modelo son los patrones que existen en ellos”.
– ¿Para interpretar los datos no hacen falta expertos que den indicaciones?
– La interpretación la hace el modelo. La influencia de quien diseña el sistema radica en su forma matemática. Por ejemplo, puede ser una red neuronal, con millones de parámetros que hay que estimar a partir de los datos. Su influencia también se encuentra en el proceso de selección y recolección de esos datos. A veces, eso incide mucho más que la forma matemática del modelo, porque va a aprender según lo que recibe. Una vez que se decidió cuáles son los datos y cuál es la forma, el resto está bastante fuera del control humano. Me refiero a lo que termina aprendiendo el modelo.
A veces, Big Data, algoritmos e inteligencia artificial parecen ser sinónimos. ¿Un algoritmo es IA?
No cualquier algoritmo. Hay una zona gris donde la distinción no es del todo clara. En la charla que brindamos en Exactas, se dijo que “tiene que estar resolviendo un problema complejo”. Eso sucede, por ejemplo, en los campos del habla, las imágenes y los textos. Todo algoritmo que esté resolviendo problemas en esos campos, asociados a entender y producir habla, texto e imágenes, es IA. En cambio, si el algoritmo simplemente da instrucciones como, por ejemplo, encontrar determinada palabra en un texto, no creo que sea apropiado decir que es IA porque simplifica demasiado el concepto.
– Mencionabas que estos sistemas pueden resolver lo mismo que nosotros…
– Pareciera que queremos reemplazar a los humanos. Suena horrible. Lo que buscamos hacer son, en general, cosas que los humanos queremos hacer aunque no siempre podemos, muchas veces por una cuestión de escalas. Por ejemplo, si pretendemos buscar un determinado archivo en una base de datos de millones de audios, es humanamente imposible. Y esto ni siquiera es “inteligencia”, sino una trivialidad que alguien podría hacer si tuviera infinito tiempo. Es una cuestión de eficiencia y de capacidad computacional. Pero la IA no se restringe únicamente a Big Data, también resolvemos un montón de problemas pequeños. En el teléfono tenemos los asistentes virtuales. Eso es IA porque está entendiendo lo que se le dice, transcribiendo el habla y respondiendo con voz sintética. Ambos lados requieren un sistema de inteligencia artificial y, además, tiene que entender qué acción llevar a cabo y ejecutarla.
– Se habla de inteligencia artificial general, que es la que podría igualar y superar a la inteligencia humana.
– En mi opinión, creo que nos falta mucho para llegar a una inteligencia similar a la humana. En principio, porque estos sistemas no saben razonar. Hay mucha gente trabajando en eso y probablemente en el corto plazo se resuelva. Existen todos los componentes para hacer que planifique. Pero le van a seguir faltando los sentidos. Va a leer texto, mirar imágenes y escuchar audio y podrá integrar todo eso, pero no es una persona que se está moviendo por el mundo. No tiene tacto, ni olfato ni gusto, y la manera en que integra la información no es dinámica. No vio la realidad en conjunto. Le está faltando una integración global de la información con causalidad temporal. Estos sistemas no experimentan el mundo.
“Creo que nos falta mucho para llegar a una inteligencia similar a la humana. En principio, porque estos sistemas no saben razonar”.
– ¿Lo harían si llegaran a tener un cuerpo robótico con sensores?
– Bueno, cuando lleguemos a tener un robot caminando que tenga sentido del tacto, el gusto, el olfato, que escuche y vea como nosotros, tal vez podamos pensar en algo parecido, pero falta muchísimo. Con suerte una vez llegado a ese punto vamos a tener mucho más regulado y entendido cómo controlar esta tecnología. La estamos creando nosotros, pensar que se puede desmadrar de un día para el otro me parece absurdo.
– Vos participaste de la declaración de Montevideo, que responde de algún modo a aquella carta abierta encabezada por Elon Musk, ¿Hay que suspender los desarrollos en IA?
– Los problemas que tenemos no se van a resolver en seis meses. Me parece inocente pensar que se puedan suspender los desarrollos. Lo que necesitamos es regulación y legislación. Creo que estuvo mal que Chat GPT saliera a la luz sin haber pasado por un proceso de inspección, algo similar a los protocolos para desarrollar un medicamento. A diferencia de la actual, que está más controlada, la primera versión que salió en noviembre no solo se equivocaba bastante sino que a veces decía barbaridades o maltrataba al usuario. No admitía que se equivocaba, era como un niño caprichoso y la gente lo usaba muy inocentemente. Pero no se puede pretender que el público comprenda el funcionamiento de una tecnología tan compleja y entienda en qué puede confiar y en qué no. El sistema debería haber sido probado por voluntarios conscientes de lo que hacen y controlado por los desarrolladores. Así, hubiera salido una versión ya inspeccionada que cumple con determinados estándares. Siempre puede haber efectos no deseados y hay que tratar de mitigarlos porque pueden ser grandes.
Para la investigadora, la IA es útil para resolver problemas específicos que las personas no quieren o no pueden resolver o para los que, en muchos casos, resultan ineficientes o poco confiables. “Tenemos que darle a la IA ese tipo de cosas, que además podemos controlar, regular e inspeccionar muy bien por dentro y por fuera del código”, propone.
Una máquina parlante
Luciana Ferrer se sorprende del nivel de habilidades al que se llegó en tan poco tiempo. La investigadora del CONICET integra el Grupo de Procesamiento del Habla, donde se dedican a procesar audio. Uno de sus desarrollos es un sistema de tutoría para el aprendizaje de inglés, enfocado especialmente a la enseñanza escolar. “El objetivo principal es que sea un software que pueda ayudar a los maestros a darle tarea a los chicos. Va a permitir corregir la pronunciación de un estudiante de inglés en un ida y vuelta uno a uno, que es algo que los docentes en el colegio tienen poco tiempo para hacer”, comenta.
El equipo, además, trabaja en la detección de estados mentales y emociones. Por ejemplo, para saber si alguien está confiando o no en un asistente virtual y que el sistema pueda reaccionar en caso de desconfianza y ser más útil. También abordaron la detección de enfermedades neurológicas como Alzheimer y Parkinson.
“Me parece inocente pensar que se puedan suspender los desarrollos. Lo que necesitamos es regulación y legislación”.
“En general, salvo para el caso del asistente de aprendizaje de inglés, no llegamos a la aplicación, hacemos investigación básica, pero sentamos las bases para que se pueda usar y llevarla a cabo”, aclara Ferrer.
La investigadora agrega que existen muchos desarrollos de asistencia al aprendizaje basados en IA y recuerda extrañada lo que sucedía hace veinte años: “Por entonces teníamos sistemas de reconocimiento y transcripción del habla donde el 40 por ciento de las palabras estaban mal y nos poníamos contentos. Ahora se puede mantener un diálogo. En aquél momento era difícil imaginar que se podría generar habla indistinguible de la humana. Es alucinante”.
Ferrer explica que, en sus inicios, para que sean razonablemente efectivos, los sistemas de dictado requerían que los adaptáramos a nuestras voces y los usáramos con un buen micrófono y en completo silencio. Ahora, en cambio, es posible estar en la calle usando el teléfono celular, sin adaptación previa, con ruido ambiente y hablando un español local, que no es el acento mayoritario con el que el sistema aprendió. “Eso es una diferencia drástica”, afirma. Y celebra: “se pasó de usar en un laboratorio para algunas pocas cosas a un uso masivo en la vida cotidiana”.
Sin embargo, la IA no se trata únicamente de procesamiento del habla. Más drástico aun es lo que pasó con el Procesamiento Natural del Lenguaje (NLP por sus siglas en inglés), que utiliza texto en lugar de señales de audio. Lo que se podía hacer hace veinte años con NLP era muy primitivo en comparación con la actualidad. Ahora se le puede pedir que escriba una novela con determinado tema y tono, y lo hace.
– ¿Qué es lo que permitió este crecimiento tan notable?
– Los modelos matemáticos cambiaron radicalmente. Desde hace poco más de diez años se utilizan, principalmente, redes neuronales, que es una tecnología que presenta una arquitectura con secuencias de capas en donde cada una hace un procesamiento y se lo pasa a la que viene. Entonces, en lugar de diseñar el modelo conociendo la tarea, el sistema aprende a resolver el problema a partir de los datos que se le brindan. El otro cambio drástico es la capacidad de computación, que es enormemente más grande. La GPU no se usaba para resolver problemas de IA hace veinte años. Lo mismo que se usa para jugar videojuegos sirve para correr redes neuronales muy eficientemente, mucho más rápido de lo que correrían en una CPU. Para entrenar Chat GPT, por ejemplo, se usaron cientos o miles de GPUs durante semanas.
– ¿Se puede decir que estos modelos piensan? ¿Cómo producen lo que dicen?
– Es probabilístico. Por ejemplo, la tarea de Chat GPT es predecir la siguiente palabra. Y con una muestra grande de Internet incorporada, está viendo un porcentaje enorme de todo lo que fue escrito por la humanidad. De un mensaje dado, va a determinar que es probable que una palabra que vio en el entrenamiento en contextos similares vaya bien para ese mensaje. La lógica es estadística. Dado un cierto texto, predice la siguiente palabra entre las más probables y así hasta que predice el símbolo de “fin de respuesta”. En parte, el resultado depende de lo que ya viene respondiendo él mismo. Tiene un conjunto de posibilidades que son todas razonables pero no hay un razonamiento.
Inteligencia artificial soberana
Al pensar en el desarrollo local de la IA, Luciana Ferrer afirma que están tratando de hacerlo. “Trabajamos en el problema de las alucinaciones, que es como se les dice a los errores y equivocaciones de los chats”, explica.
A su vez, comenta lo complicado de abarcar modelos tan grandes: “Lo que estamos haciendo es correr modelos viejos, más chicos, que entran en la computadora que tenemos. Creo que en el corto plazo eso se va a ir resolviendo. Mucha gente está generando nuevos modelos open source en los que su proceso de entrenamiento es público”, manifiesta la investigadora. Y suma: “Creo que a corto o mediano plazo va a ser posible tener algo razonablemente parecido a lo que tiene Open AI. Si se achican un poco los modelos y adquirimos equipamiento más grande podremos entrenar desde cero nuestros propios desarrollos”.
Al igual que en otros rubros, la dependencia e inequidad respecto a las potencias mundiales es notoria con estas tecnologías. En materia de lenguaje, cultura, y sesgos, resulta algo evidente. Open AI, por ejemplo, también generó datos a mano con gente que fue indicando cómo prefería que el chat responda ante determinadas preguntas. “El problema de eso es que se trata de gente de una determinada cultura. Las respuestas correctas, ¿aplican a una cultura diferente? Hay un montón de sesgos”, advierte.
Sin embargo, el principal problema, precisa Ferrer, es la producción de datos: “La mitad de Internet está en inglés, no vamos a tener nunca ese volumen de datos para los demás idiomas”, concluye.